 Deze blogreeks valt binnen ons thema ‘Management & BI’. Dit thema is bedoeld voor managers die wat meer willen weten over Business Intelligence, maar dan alleen de essentie, in begrijpelijke taal en zonder alle technische termen en hypes.
Deze blogreeks valt binnen ons thema ‘Management & BI’. Dit thema is bedoeld voor managers die wat meer willen weten over Business Intelligence, maar dan alleen de essentie, in begrijpelijke taal en zonder alle technische termen en hypes.
Big Data en Data Science gaan een steeds grotere rol spelen binnen Marketing Intelligence. Het benutten van data uit open data sources, uit sociale media en zelfs uit sensoren in het veld (IoT) wordt snel interessanter. Het leren uit dit soort data kan positieve effecten hebben op het succes van je marketing efforts, daar hebben we het in deze blogreeks al vaker over gehad. Ik krijg daarbij vaak de vraag “Maar hoe richt ik dat in? Heb ik een data lake nodig en waar positioneer ik die dan?”. Daarom leek het me goed om een ruwe, high-level schets te geven van de mogelijke positie van een marketing data lake. Daarin vind je big marketing data terug en geef ik gelijk aan waar data science een rol speelt in de BI-omgeving van Marketing.
De positie van het Marketing Data Lake
Hieronder staat een high-level schets van een BI-omgeving voor Marketing, met daarin aangegeven de positie van zowel het Marketing Data Lake als Marketing Data Science.
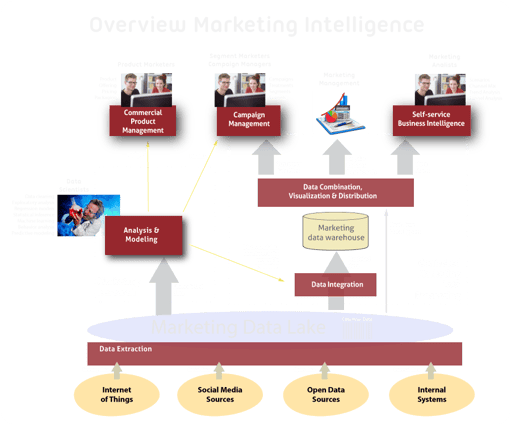
Data bronnen voor het Marketing Data Lake
Het marketing data lake is onderdeel van het werkveld van de data engineer. Hij zorgt voor de correcte verzameling van alle data, de column-based opslag in het lake en de distributie van data uit het lake naar afnemers. De belangrijkste vier, potentiële bronnen voor big data zijn:
- Interne bronnen, denk bijvoorbeeld aan website tracking data, klantgedrag in winkels, productgebruik. Deze data kan soms heel gedetailleerd worden verzameld en daardoor snel groeien.
- Sociale media, zoals tweets, likes, messages, enzovoorts.
- Sensory data uit het Internet of Things (IoT). Indien relevant kan dit een constante stroom aan gegevens over klantgedrag en productgebruik opleveren.
- Open sources met data uit allerlei openbare bronnen, bijvoorbeeld de (semi-)overheid, onderzoeksinstellingen en publieke websites. Het aanbod van dit soort open data groeit gestaag. Onze eigen overheid heeft al aangegeven dat veel van haar gegevens openbaar moet worden gemaakt (zolang de privacy maar niet geschaad wordt).
Flexibele data opslag voor Marketing
In principe is het mogelijk om alle data eerst te verzamelen in een data lake. Het gaat dan om zowel de geborgde en gestructureerde data, als de nog te modelleren, ongestructureerde data. Je kunt er ook voor kiezen om het data lake alleen voor ongestructureerde marketing data te gebruiken. Zo vermijd je mogelijke verstoringen van de reguliere, geborgde datastromen door het marketing data warehouse. Het andere uiterste is om een data lake voor de hele organisatie in te richten van waaruit – naast Marketing - alle disciplines de voor hun relevante data onttrekken.
Een discipline als Marketing hecht meestal grote waarde aan flexibiliteit waarbij nieuw gevonden, interessante data snel moeten kunnen worden geborgd in de managementinformatie. Bij bijvoorbeeld Financiën zou dat juist minder belangrijk zijn. Voor Marketing is vaak zinvol om het data lake te vullen met zowel gestructureerde als ongestructureerde data – zoals in de afbeelding hierboven weergegeven. Als je dan binnen marketing research dan ontdekt dat bepaalde data waardevol zijn, dan kun je deze data sneller in je reguliere marketing data warehouse krijgen, omdat je data warehouse ook is aangesloten op hetzelfde data lake en je dus de data niet opnieuw hoeft te ontsluiten. Op deze manier voorzie je vanuit het data lake twee grote gebieden van data:
- De reguliere en goed geborgde data verwerking via het data warehouse
- Het research gedeelte van marketing. Hier zit het data science hart van marketing.
De positie van Marketing Data Science
Veel van de nieuwe data sources zoals open data, social data en sensory data worden eerst in het marketing research lab onderzocht. We kijken hierbij vooral naar de bedrijfswaarde van de data in de context van marketing. Welke data zijn verklarend, heeft voorspellende waarde? Waarvan is prospect/klantgedrag afhankelijk? Kan ik naar aanleiding van het werkelijk gebruik van mijn producten of diensten, verbeteringen aanbrengen in mijn proposities? Kan ik voorspellen wanneer een klant churn vertoont en wat zijn daarbij de belangrijkste indicatoren?
De data scientist die deze vragen adresseert, heeft – naast een goede onderzoeksvraag – ook allerlei data nodig die hij zelfstandig uit het data lake haalt. Zijn de benodigde data nog niet aanwezig dan stopt hij die er zelf in - eventueel met hulp van de data engineer.
De inzichten uit marketing data science kun je delen met product marketers en segment marketers. Nieuwe voorspellende modellen kun je doorgeven aan campaign management om na kalibratie te worden gebruikt voor segmentatie en next best actions. Het zal blijken dat veel data na onderzoek niet van toegevoegde waarde blijken te zijn. Maar de data die wel bijdragen aan het succes zullen in aanmerking komen om geborgd te worden in het marketing data warehouse. Daarmee komen deze nieuwe data als informatie tevoorschijn in de dashboards en BI-tools van je marketing managers.
Conclusie
Natuurlijk is dit een high-level schets en deze opzet hoeft voor jouw marketingdiscipline niet perse de meest optimale inrichting te zijn. Toch leek het me handig om eens een plaatje op te stellen aan de hand waarvan je de positionering van big data, data lakes en data science bespreekbaar kunt maken.
Ben je nieuwsgierig wat de opkomst van Marketing Intelligence en Big Data nog meer voor jouw organisatie kan betekenen? Onderstaand eBook geschreven door Gerrit Versteeg geeft onder andere antwoord op deze vragen.

Laat hieronder een opmerking achter als je een bepaald onderwerp rond Marketing Intelligence wilt aandragen. Dan kan het zomaar voorkomen dat jouw situatie of vraag in een dedicated blog binnen de reeks wordt besproken.