 Deze blogreeks valt binnen ons thema ‘Management & BI’. Dit thema is bedoeld voor managers die wat meer willen weten over Business Intelligence, maar dan alleen de essentie, in begrijpelijke taal en zonder alle technische termen en hypes.
Deze blogreeks valt binnen ons thema ‘Management & BI’. Dit thema is bedoeld voor managers die wat meer willen weten over Business Intelligence, maar dan alleen de essentie, in begrijpelijke taal en zonder alle technische termen en hypes.
In vervolg op mijn blog van afgelopen week duiken we nog wat dieper in de strijd die lijkt op te laaien tussen aanhangers van Big Data en aanhangers van data warehouses. Als je dat nog niet gedaan hebt, is het raadzaam om het eerste deel van deze blog eerst even te lezen voordat je aan dit tweede deel begint.
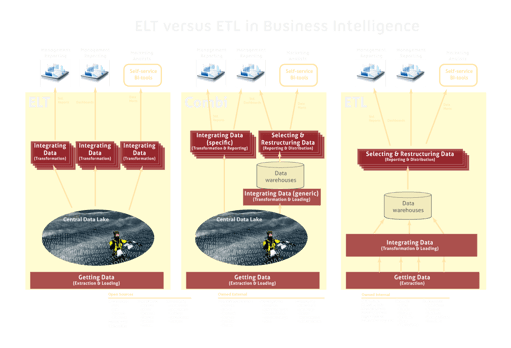
Klassiek (ETL)
Het streven naar het vroegtijdig leggen van relaties tussen data, vindt haar 'extreem' in het streven naar één datamodel voor het hele bedrijf. Een dergelijk bedrijfsbreed datamodel wordt ook vaak geassocieerd met de term 'Enterprise Data warehouse'. Het streven naar één integraal datamodel kent in de praktijk twee belangrijke nadelen:
- Het leggen van de relaties (i.e. het integreren van data) wordt lastiger naarmate de scope van de integratie (het aantal bronnen, het aantal talen) groter wordt, niet alleen in het vaststellen van de integratie-regels, maar ook in de praktische uitvoering van het integratieproces. Hierdoor neemt de verversing van je BI-omgeving steeds meer tijd in beslag, met het risico om achter te gaan lopen, en krijg je een steeds hoger wordende time-to-market voor nieuwe informatieproducten.
- Een bedrijfsbreed datamodel kan niet zonder één uitleg (semantiek) van de bedrijfstaal (ontologie). De werkelijke praktijk van een bedrijf kent echter helemaal geen eenduidige terminologie. Dat houdt dus in dat een 'kunsttaal' á la Esperanto moet worden opgesteld. Een dergelijk proces verloopt uitermate moeilijk en moeizaam en daarbij is een uiteindelijk ontworpen taal ook nog eens slecht onderhoudbaar (zie ook H4 van het eBook "the 10 need to knows rond BI").
Mitigatie van de risico's rond één bedrijfstaal
Om de problemen rond een bedrijfsbreed datamodel te voorkomen, kun je ook eens kijken naar het gebruik van de vaktaal van management-disciplines. Managementdisciplines hanteren vaak onderling verschillende termen, gedreven door hun vakgebied. Denk bijvoorbeeld aan finance versus marketing of operations. Regelmatig gebruik ik in BI-architecturen daarom liever meerdere datamodellen die elk afzonderlijk specifiek bedoeld zijn voor een bepaalde discipline, zodat de termen beter en meer natuurlijk en herkenbaar kunnen convergeren.
Het voordeel van de ETL-aanpak
Het leggen van de relaties tussen data gebeurt vaak in het kader van de context van het bedrijf. Meerdere informatieproducten, zoals management-rapporten en –dashboards, delen die context en hebben dus dezelfde relaties nodig. Het voordeel van vroeg, meer centraal en gebruiksonafhankelijk relaties leggen tussen data, is dat de logica voor het leggen van die relaties gemeenschappelijk en daarmee eenduidig wordt. De integratielogica overstijgt de managementinformatie. Hierdoor ontstaan minder interpretatieverschillen over cijfers en minder versnipperde - en dus al snel inconsistente en lastig onderhoudbare - logica in het genereren van de managementinformatie (MI).
Big Data (ELT)
Het zo laat mogelijk leggen van relaties, dus zo ver mogelijk naar het gebruik toe, heeft als belangrijk voordeel dat die relaties gelegd worden 'in de beperkte ontologische context (de taalruimte)' van een specifiek gevraagd MI-product. En, zoals gezegd, als de scope van de integratie (het leggen van relaties) kleiner wordt, is de integratie eenvoudiger.
Een vervelend feit is echter dat er altijd relaties tussen data zijn te vinden die gelden voor meerdere MI-producten en zelfs voor alle MI. Het naar 'voren' drukken van de data-integratie, betekent dat de integratie-logica terecht komt in de generatie-functie van MI-producten. Met als belangrijk nadeel dat ook de gemeenschappelijke integratie-logica wordt versnipperd en gedupliceerd over de generatie-functie van die MI-producten. Als gevolg daarvan ontstaat dan al snel een lagere onderlinge consistentie van de integratie-logica en dus verschillende interpretaties van de resulterende cijfers. Ook het aanbrengen van wijzigingen in die gemeenschappelijke integratie-regels wordt daarmee op termijn lastiger en moeizamer.
En toen?
Big Data heeft ruimte nodig
Om de 'gulden middenweg der deugden' van Aristoteles maar eens aan te halen: we moeten ergens in het midden belanden in een situationele weging van voor- en nadelen. De oorzaak van de hele Big Data beweging ligt in de sterk groeiende overvloed van waardevolle, maar vaak ruwe data uit externe bronnen. Deze externe bronnen zijn niet beïnvloedbaar, waardoor het inrichten van meer ruimte voor databewerking en -verwerking (voordat je überhaupt relaties kan leggen) belangrijk is. Die ruimte krijgt tegenwoordig vaak vorm middels data lakes en de bijbehorende technologie (bijvoorbeeld Hadoop stacks, zoals Cloudera en Hortonworks). Relaties die uit de inhoud van de data blijken, leggen we het liefst vast in aparte files of tables met zogeheten 'triples'. Dat zijn subject-predicate-object combinaties, zoals "CO2 heeft een nadelig effect op Ozon". En dus niet in een datamodel met 'ontworpen' relaties.
Geef de gemeenschappelijke logica een plek
Het inrichten van die ruimte hoeft echter niet te betekenen dat we de integratie van data tot MI maar moeten uitstellen tot we echt MI-producten gaan maken. Ergens moeten we de potentiële valkuil om alle (dus ook gemeenschappelijke) integratielogica te verspreiden over MI-producten tegengaan. Zo verzanden we niet in inconsistente, moeilijk onderhoudbare en slecht presterende rapportages en dashboards. Na het data lake, maar nog voor we bij de uiteindelijke MI-producten terechtkomen, kunnen we een functionele laag positioneren waarin we de gemeenschappelijke integratielogica een plek geven. Dat is een plek voor gemeenschappelijke relationele modellen of multidimensionale modellen met gemeenschappelijke ('conformed') dimensies. Dat vormt ook meteen een goede plek om interne data te combineren met externe data. Dat is de nieuwe plek voor mogelijke data warehouses, maar dan niet in de zin van het (door Big Data aanhangers verfoeide woord) Enterprise Data warehouse.
Conclusie
De tegenwoordige overvloed van ruwe data uit externe bronnen waartussen niet direct relaties gelegd kunnen worden, levert ons het momentum om van het ETL-beginsel af te gaan stappen. We kunnen de data simpelweg niet direct integreren. Het vormt een extra argument tegen het klassieke, vaak nodeloze mantra "je moet alle data eerst in één datamodel stoppen om een centrale versie van de waarheid te hebben". De externe, ruwe data moeten we eerst gewoon onverkort opslaan en onderzoeken voordat we er (statistische) relaties in kunnen leggen.
Big believers van Big Data stellen dat je moet proberen om alleen op het laatste moment relaties te leggen (ELT). Dat is best logisch vanuit hun blik op die externe, ruwe data, maar is vaak ook een reactie voortkomend uit de opgebouwde frustratie rond de praktische onhaalbaarheid van het hiervoor genoemde klassieke BI-extreem, waar alle data eerst maar in één groot datamodel terecht moet komen.
In de praktijk
De ruimte voor Big Data is nodig, maar er moet óók ruimte gereserveerd worden voor de integratie-logica die gemeenschappelijk is over MI-producten heen. Daarmee vermijd je dat deze logica versnipperd wordt over MI-producten. Binnen die ruimte zien we de 'nieuwe' plek verschijnen voor datamodellen en data warehouses. We moeten daarbij wel nadrukkelijk proberen om af te zien van het praktisch vaak onhaalbare bedrijfsbrede datamodel en het daarmee geassocieerde enterprise data warehouse. Liever gebruiken we bij gemeenschappelijke en doelgerichte data-integratie meerdere, losse datamodellen. Let wel, dat is iets anders dan de term 'data marts' zoals deze door Big Data aanhangers wordt gedefinieerd. Zij zien een data mart als een MI-product met één specifiek doel, dus ook juist als tegenhanger van de meer gemeenschappelijke data warehouses.
Ondanks een mogelijke polarisatie tussen de twee aanpakken, "hoeft er geen duivel te liggen tussen twee geloven op één kussen! Als je de geloofsovertuigingen maar minder stringent opvat en meer praktisch interpreteert en combineert.
Meer weten?
Download onderstaand eBook voor meer informatie over BI. Naast talloze tips en best practices, bevat dit 100 pagina lange eBook de tien belangrijkste wetenswaardigheden rond Business Intelligence. Beschreven vanuit het gezichtspunt van de manager en zoveel mogelijk ontdaan van technische ICT-termen.

Laat hieronder een opmerking achter als je een bepaald onderwerp rond Business Intelligence wilt aandragen. Dan kan het zomaar voorkomen dat jouw situatie of vraag in een dedicated blog binnen het thema wordt besproken.